【94.5%精度登顶全球!百度开源0.9B“小钢炮”OCR模型】
你是否有过这样的经历?用手机拍下一张发票准备报销,财务却说“表格歪了识别不了”。这些因文档形变导致的数据混乱,正是OCR技术长期面临的难题。
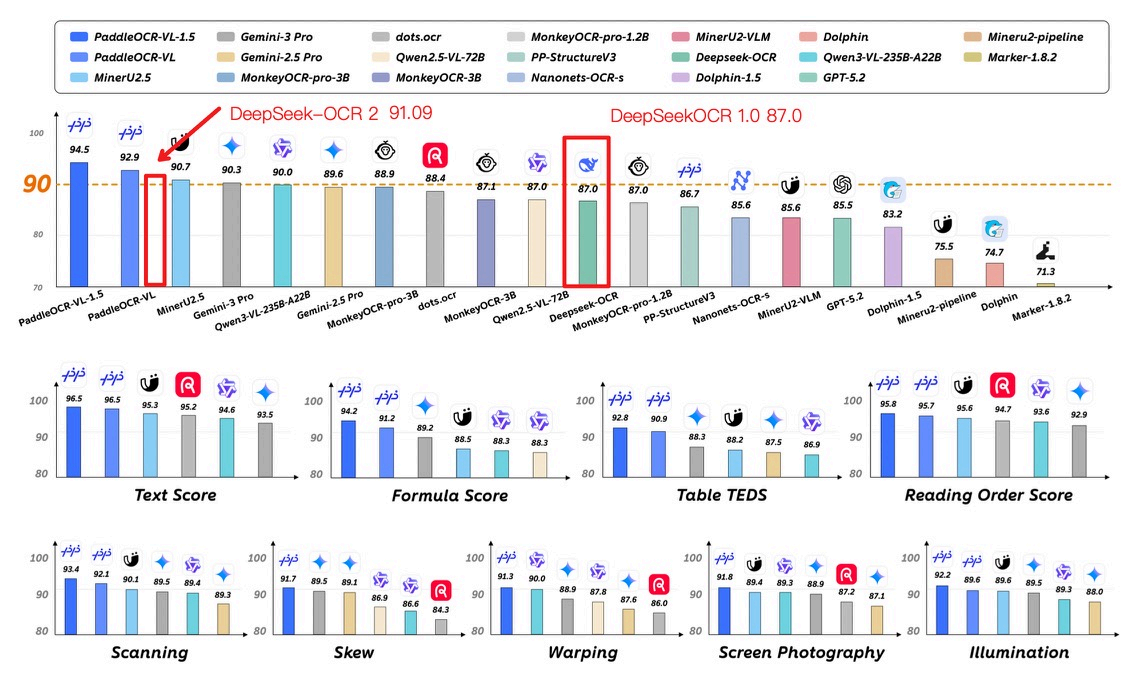
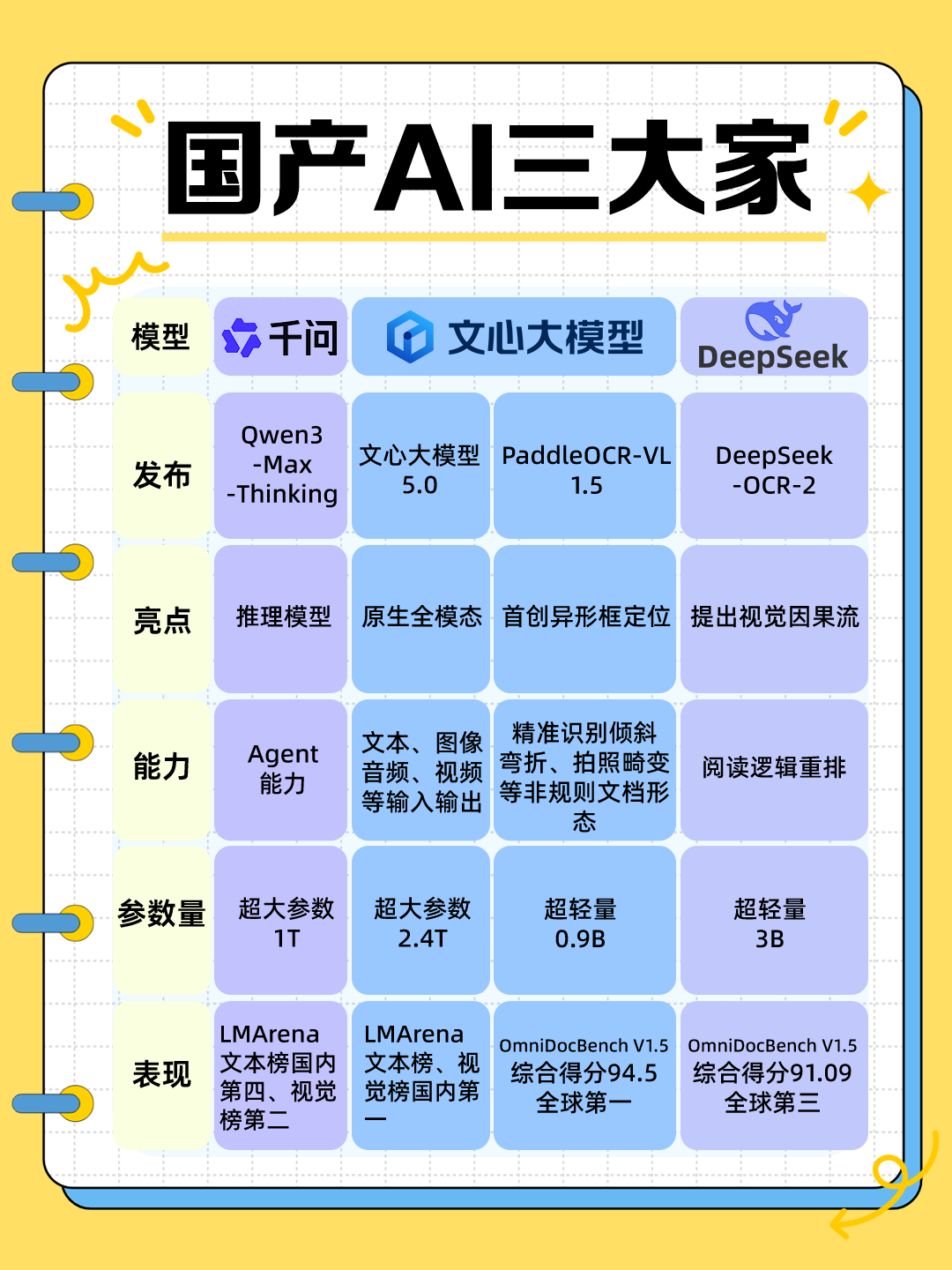
1月29日,百度发布的PaddleOCR-VL-1.5模型,正是为解决这一问题而来。这项基于文心大模型研发的新一代文档解析技术,在全球权威评测OmniDocBench V1.5中,以94.5%的综合精度登顶榜首,性能超越了包括Gemini-3-Pro、DeepSeek-OCR2在内的诸多国际知名模型。
它的核心“杀手锏”,是一项名为“异形框定位”的全球首创能力。传统OCR模型本质上是基于“矩形世界”的假设进行设计的,对于任何非水平的线条和区域都束手无策,只能识别文字,无法还原结构。而PaddleOCR-VL-1.5则让AI第一次真正“看懂”了文档的几何形态。无论是倾斜拍摄的名片、弯折褶皱的票据,还是因透视变形呈梯形的白板照片,模型都能像一位经验丰富的文员,精准地“勾勒”出每一个单元格、每一段文本的真实边界,并将扭曲的内容自动“拉正”,还原出规整的数字化结构。
这一突破的技术价值,直接体现在其评测成绩单上:在表格结构理解任务中,它以92.8分位列第一;在阅读顺序预测这一决定文档逻辑的关键任务上,更以95.8分的高分领先,其逻辑解析错误率仅为同类模型的一半左右。这意味着,在处理复杂的合同、财报或多页报告时,新模型的输出不仅文字准确,更能保持原文的排版逻辑和数据关联性,实现了从“识字”到“懂文”的本质跨越。
除了核心的结构理解能力,该模型在实用性上也做了全面增强。它新增了对藏语、孟加拉语的支持,并专门优化了对古籍文献、生僻字、多语种混合表格乃至表单中下划线、复选框等复杂元素的识别能力。对于长文档,它还支持跨页表格的自动合并与标题的连贯识别,有效解决了信息断裂的问题。
值得强调的是,如此强大的能力,被封装在一个仅有0.9B参数的轻量级模型中。这意味着更高的部署效率和更低的计算成本,让尖端技术得以更快地飞入寻常企业。目前,PaddleOCR-VL-1.5已在GitHub和Hugging Face上全面开源,开发者可以免费获取并商用。普通用户也可以通过PaddleOCR官网的在线演示,立即体验这款“文档校正神器”的魅力。
从文心大模型的持续进化,到其衍生模型在垂直领域的精准突破,百度在2026年开年展现了中国AI产业扎实的技术推进力。PaddleOCR-VL-1.5的发布,不仅是一项技术的胜利,更是AI真正理解物理世界、解决实际业务痛点的重要里程碑。