(一)
不得不说,最近的AI圈,又被谷歌刷屏了。
11月18日,谷歌正式发布Gemini 3系列模型,各大科技媒体、开发者社区瞬间炸锅。什么"断层式碾压"、什么"一夜封神"、什么"新王登基",各种溢美之词铺天盖地。
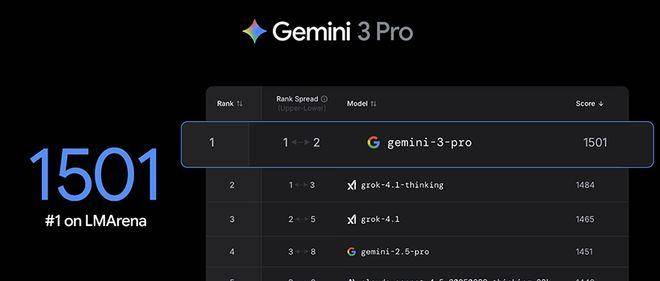
LMArena评分1501登顶榜首,数学能力23.4%秒杀全场,ARC-AGI测试31.1%甩开GPT-5两倍……
哪知道,这些漂亮的数字背后,真实情况远不止大家看到的那么美好。
我测试了几天Gemini 3 Pro,坦率地说,有些话憋在心里不吐不快。
全网都在喊"真香"的时候,是时候冷静一下了。
(二)
先说最让人无语的——提示词遵循能力。
这可能是Gemini 3最大的槽点。
知乎上有位开发者直言不讳:"提示词遵循能力太烂了。"现阶段测试下来,在严格遵循用户指令这件事上,Gemini 3 Pro竟然排在GPT-5 Pro、Opus 4.1甚至Grok 4.1之后。
更离谱的是,Gemini 3输出的稳定性过分倾向于它宣传的那几个功能——前端代码生成、论文复现、多模态理解。
如果你的需求恰好在这些领域,那确实很香;但如果你想让它老老实实按你的要求做点别的,对不起,它经常有一种"鸡同鸭讲"的感觉。
有开发者测试发现,同样的任务,更简单的提示词就能让GPT-5或Claude Sonnet 4.5一次搞定,但Gemini 3需要反复调整提示词才能达到预期效果。
这很谷歌——技术秀得飞起,实用性却打折扣。

(三)
还有那个让全网高潮的"数学能力"。
MathArena竞赛23.4%的成绩,确实吊打其他模型的1%左右。但仔细看测试案例就会发现问题。
有位自动驾驶工程师设计了4道PointNet相关的面试题,Gemini 3确实全对了。但他紧接着测试了一道财务税收计算题——结果Gemini 3把"税"理解成了"手续费",整个推理过程南辕北辙。
更诡异的是,当用户明确指出"这是税务问题而非手续费"后,Gemini 3才恍然大悟给出正确答案。
问题来了:一个号称"博士级推理能力"的模型,连题目中明确说明的"预征收个人所得税"都理解不了?
这不是数学能力的问题,而是常识理解和上下文把握的问题。
有开发者一针见血:"Gemini翻车的并不是数学能力,而是财务理解能力。"
再看看谷歌引以为傲的"复现论文"功能。
如果论文内容基础、进入了教科书,效果确实好到离谱;但测试一篇复杂的生物学数学建模论文,30个参数、多层假设——结果是"灾难性得糟糕"。
这说明什么?Gemini 3的能力高度依赖训练数据覆盖。遇到成熟领域就是学霸,碰到前沿课题立刻原形毕露。
(四)
最后,还是忍不住要感叹一下。
谷歌啊谷歌,你怎么又玩这套?
当年AlphaGo横空出世时,全世界都在惊叹谷歌的技术实力。但后来呢?TPU只给自家用,开源模型迟迟不见踪影,Android越来越臃肿……
现在的Gemini 3,又是一个典型的"谷歌式产品":
技术Demo炫得飞起——一句话生成3D游戏、SVG矢量图秒出、多模态理解碾压全场;
实际体验槽点满满——提示词遵循拉胯,理解偏差时有发生;
定价策略高高在上——API成本全行业最贵,还美其名曰"性能优越理应如此"。
更关键的是,Gemini 3所谓的"断层式领先",很大程度上是因为谷歌把整个生态都绑在了一起——TPU提供算力、搜索承担入口、Android和Chrome撑起交互层、Workspace负责执行任务。
这种"平台级碾压",本质上是用生态优势碾压技术竞争。
对手们并不是技术不行,而是根本没有这套完整的牌可打。

(五)
说了这么多,我并不是否认Gemini 3的价值。
它在多模态理解、前端代码生成、视觉识别等方面,确实达到了新高度。那些一句话生成可玩游戏的Demo,也足够惊艳。
但我想说的是:
AI模型不是跑分比赛,更不是技术堆砌的秀场。
一个好的AI助手,应该是能准确理解用户意图、稳定输出预期结果、成本可控且易于集成的工具。
从这个角度看,Gemini 3还有很长的路要走。
更重要的是,当全网都在无脑吹捧的时候,我们需要有人站出来说点真话。
AI行业已经够浮躁了,各种"遥遥领先"、各种"碾压友商"、各种"改变世界"……
结果呢?大部分产品都是PPT造火箭,真正落地能用的寥寥无几。
Gemini 3确实强,但远没有宣传的那么神。
(作品声明:来源网络公开资料,个人观点、仅供参考)