在 LLM 评估体系日益依赖 "大模型担任评估者"(LLM-as-a-Judge)的今天,一个隐秘且严重的问题正在扭曲大模型的评估生态:偏好偏差。
即使是性能强劲的 GPT-4o 和 DeepSeek-V3,在进行成对答案比较时,也会系统性地偏爱特定输出 —— 尤其是自己生成的内容。这种偏差导致不同裁判模型给出的评分和排名天差地别。论文中的实验数据显示,在 ArenaHard 数据集上,自我偏好偏差幅度从 - 38% 到 + 90% 不等。当模型既是 "运动员" 又是 "裁判" 时,公平性无从谈起。
现有解决方案依赖提示工程、模型集成或博弈论重排等,但这些方法要么缺乏理论支撑,要么成本爆炸,要么难以扩展。更重要的是,它们都依赖人工设计的规则,没有办法让大模型输出统一的结果。
UDA 的出现,为破解这一困局提供了新思路。来自智谱 AI 的研究团队将无监督学习引入成对 LLM 评判体系,让模型能够自主动态调整评分规则,实现去偏对齐。
该论文已被 AAAI 2026 录用。
 论文标题:UDA: Unsupervised Debiasing Alignment for Pair-wise LLM-as-a-Judge
论文链接:https://arxiv.org/pdf/2508.09724
代码仓库:https://github.com/zhang360428/UDA_Debias
论文标题:UDA: Unsupervised Debiasing Alignment for Pair-wise LLM-as-a-Judge
论文链接:https://arxiv.org/pdf/2508.09724
代码仓库:https://github.com/zhang360428/UDA_Debias 评判偏差:大模型担任评估者的 "偏好之困"
现有的 LLM 评判系统(如 Chatbot Arena)普遍采用 Elo 评分机制,但面临着三类挑战:
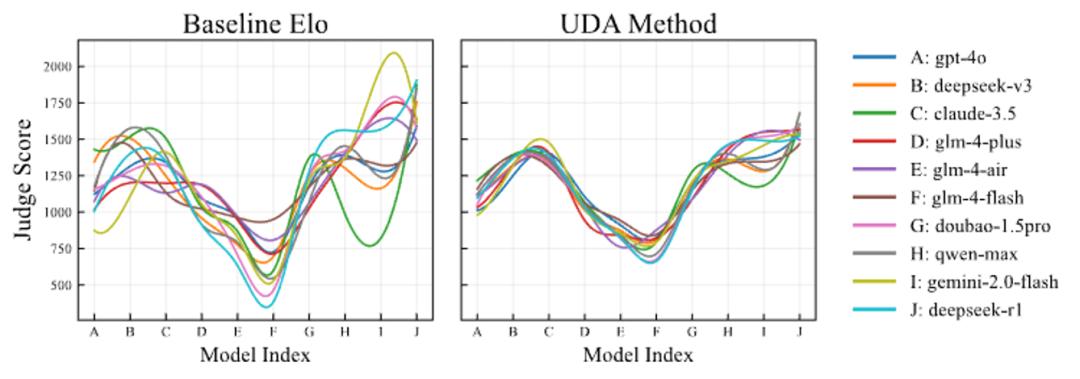
自我偏好固化:模型系统性高估自己生成的答案,导致 "谁当裁判谁占优" 的荒谬局面; 异质性偏差:不同模型的偏差方向与强度各异,从激进自夸到过度谦逊不一而足; 静态评分缺陷:传统 Elo 使用固定 K 因子,无法区分关键对决与平庸比较,小样本下信噪比极低。结果就是 "评分失准"、"排名震荡" 频发:如下图所示,在未经优化前,10 个主流 LLM 裁判对同一组答案给出的 Elo 分数标准差最高能达到 158.5 分,评分轨迹如脱缰野马般离散。而经过 UDA 对齐后,各裁判轨迹显著收敛,共识稳定度提升近 60%。
UDA 的核心贡献在于将去偏问题转化为一个可通过动态校准优化的序列学习问题。与以往依赖人工规则或监督信号的方法不同,UDA 让评判者在处理每对比较时自主探索最优的评分策略,并通过共识最小化目标直接获得反馈。这种无监督的优化方式使模型能够学习到较为公平的对齐机制。

方法框架
如图所示,UDA 将成对评估建模为实例级自适应过程。对每个裁判模型 k,当比较答案对 (ai, aj) 时,系统提取多重特征,通过轻量级网络动态生成调整参数,最终输出校准后的 Elo 更新。训练过程中通过共识锚定目标获得反馈。被训练的适配器 () 专注学习去偏策略,固定的 Elo 系统 (❄️) 负责基础评分。
特征工程与自适应网络
UDA 的精髓在于人类标注无关的特征构建。对每对比较,系统提取基于语义的特征向量 φ(k) ij,涵盖:
高维特征:答案嵌入间的 element-wise 差值、归一化积,捕捉语义风格差异 标量特征:余弦相似度、KL 散度、长度差异,量化分布距离 自我感知特征:裁判自身答案与候选答案的相似度,作为偏差预警信号这些特征无需任何人工标注,完全从响应分布中自动构建。
一个三层 MLP 网络 fθ 随后将特征映射到自适应参数:
实例级 K 因子 Kij:动态调整每轮比较的权重,可疑对决自动降权 软标签 (si, sj):替代硬判决,缓解偏好噪声,实现平滑更新共识锚定:无监督对齐的基石
UDA 的核心创新是无监督的共识驱动训练。在缺乏 "黄金标准" 的困境下,UDA 将所有裁判的集体共识视为一个现实可用的优化目标。虽然共识并非完美真值,但实证表明,异质性偏差在聚合时倾向于相互抵消。
训练目标巧妙设计为多任务损失:
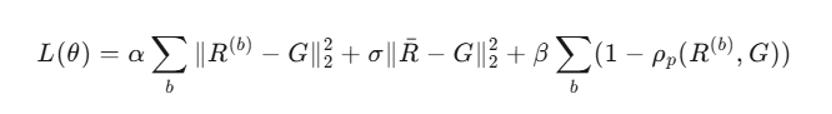
三项分别驱动:(i) 各裁判轨迹向共识收敛,(ii) 保持排名相关性,(iii) 强化集体一致性。最终,UDA 不追求复制共识,而是以共识为锚,压制极端个体偏好。
理论动机:为什么共识对齐能减少偏差?
UDA 的核心理论洞见是:对齐多样化裁判的共识,将降低系统总偏差。
证明:设 Ri 为模型 i 的真实 Elo 分数,ε(k) i 为裁判 k 的偏差项。在线性收缩模型下(实际情况当然会比该假设复杂,但这种趋势是相同的),UDA 对齐后的预期总绝对偏差不超过基线:

证明思路:对齐过程可视为向平均偏差的凸组合收缩,通过三角不等式和 Jensen 不等式即可得证。虽然个别校准良好的裁判可能轻微牺牲精度,但集体方差缩减主导了个体成本。
这一理论为无监督对齐提供了动机:即使共识本身有噪声,减少离散度仍能提升整体可信度。
实验结果
UDA 在 ArenaHard(500 问题,10 大模型,45 万对比较)上训练,在零样本迁移中展现了非常好的效果:
主实验
训练集与测试集上不同大模型评估的方差:

测试集上评估结果与人类评估的相关性系数:

四大核心发现:
1. 跨模型方差锐减:UDA 将平均裁判间标准差从 158.5 降至 64.8(↓59%),最激进的 gemini-2.0-flash 偏差从 341.9 压缩至 128.8,证明对极端偏差的强效抑制。
2. 人类对齐跃升:在人工标注迁移集上,UDA 将平均 Pearson 相关性从 0.651 提升至 0.812(+24.7%),将弱裁判(如 glm-4-flash)提升至与顶尖行列大模型(deepseek-r1)相当水平,实现评估民主化。
3. 零样本迁移稳健:在未见过的新的迁移数据集上,UDA 未经重新训练仍实现 63.4% 的方差缩减,证明领域无关的去偏能力。
4. 自我感知特征的决定性:消融实验显示,移除大模型自身回答相关特征后,虽然方差进一步降至 65.64,但人类相关性暴跌至 0.510。这可能是因为缺乏自我意识的模型会盲目收敛,却是却偏离人类真值。
消融研究:自我感知特征的关键作用
为验证所选特征的必要性,该研究团队训练了 UDA(Ablated)变体,剔除所有与裁判自身答案相关的特征:
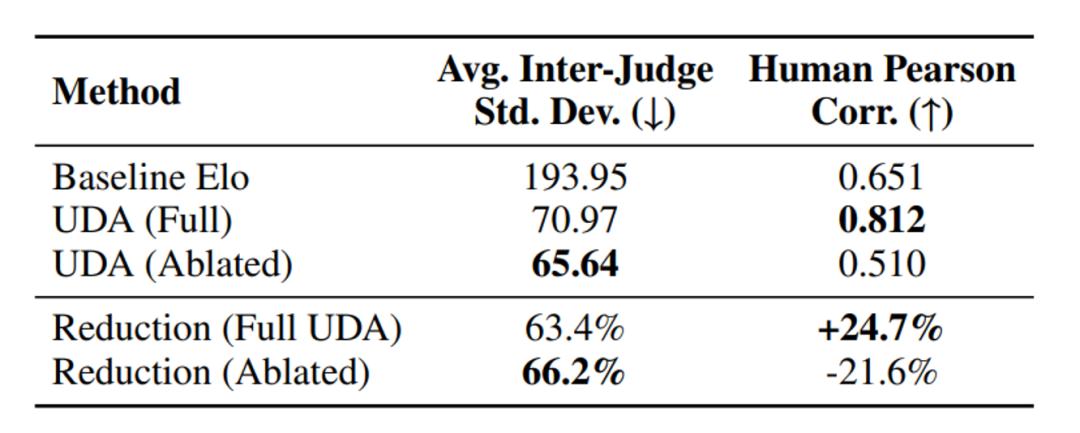
实验结果显示:剔除自我感知相关特征后,模型过度优化共识一致性,牺牲了人类对齐。自我感知特征如同 "偏差镜子",让裁判能识别并折扣自身偏好,从而引导集体判断朝向客观真值。
总结
UDA 让我们看到一个重要趋势: "评判校准不再是提示工程问题,而是可以被学习的问题。" 通过无监督共识信号,模型不再依赖人工撰写的去偏提示,而是在交互中自主演化出公平评分策略。
这项研究针对现有评估中不同 LLM 评委存在的系统性自偏好偏差以及评分不一致问题,通过轻量级神经网络动态调整 Elo 评分系统的 K 因子与胜负概率,实现实例级别的去偏矫正正。其核心思想是将所有评委评分的集体共识作为无监督优化目标,通过最小化各评委 Elo 轨迹的离散度来抑制极端个性偏差,同时利用评委自身回答的语义等特征检测自偏好倾向。该框架有效提升了低质量评委的表现,使其接近高质量评委水平,显著增强了评估的鲁棒性、可复现性与人类对齐度。