[LG]《Do Stop Me Now: Detecting Boilerplate Responses with a Single Iteration》Y Kainan, S Zychlinski [JFrog] (2025)
Do Stop Me Now: 以首个生成词预测模板化回复,实现LLM推理高效优化
大语言模型(LLM)在生成对话时,常会产生大量模板化回复,如拒绝回应、简单致谢或问候,这些内容虽无需复杂计算,却消耗大量资源和时间。本文提出一种简洁高效的方法:仅通过分析模型生成的第一个词的对数概率分布,即可准确分类回复类型,判断是否为模板化回复。
核心发现:
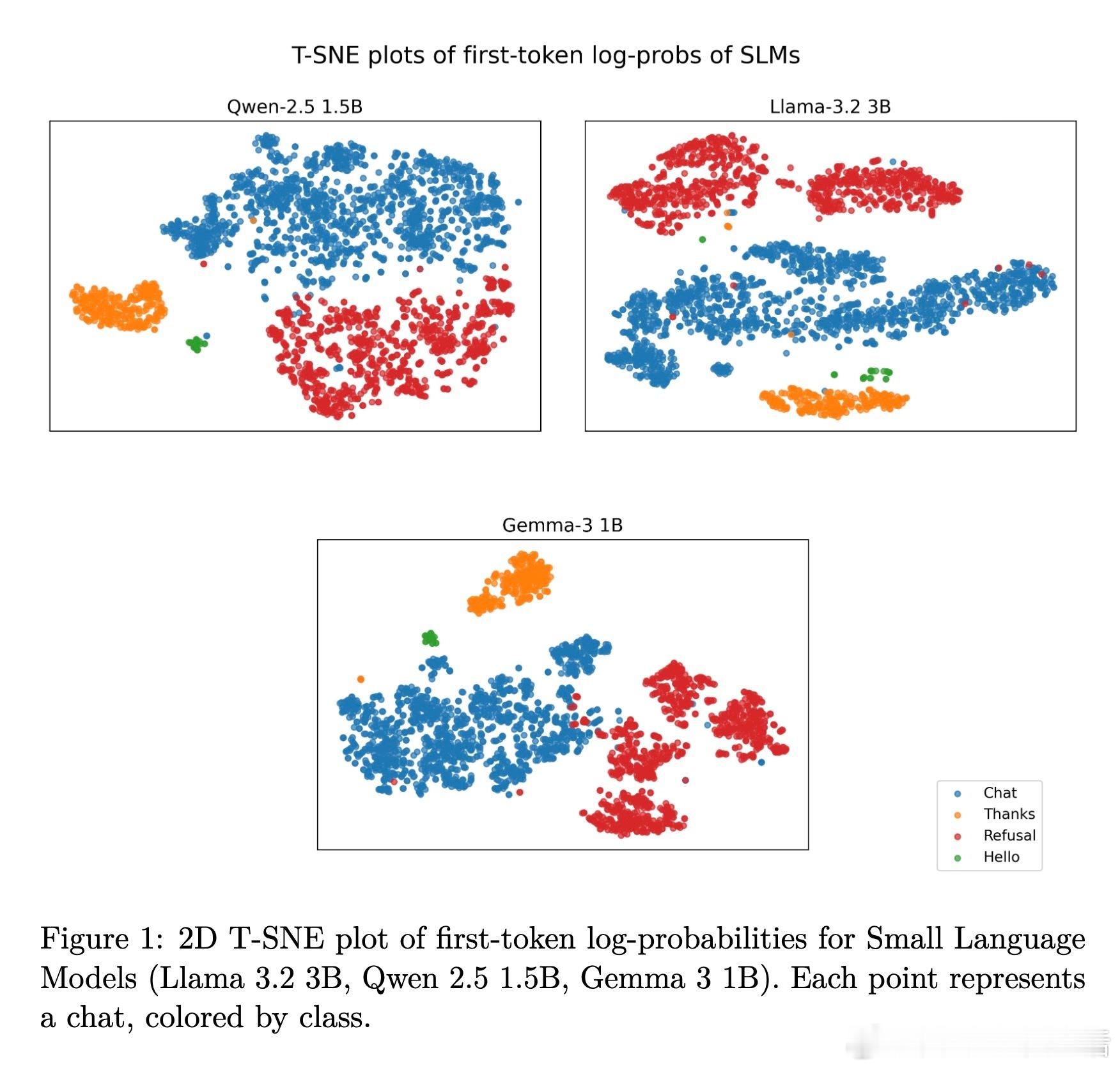
1. 第一个生成词的对数概率向量在不同回复类别(如拒绝、问候、感谢及正常聊天)间形成明显可分的簇。
2. 利用轻量级的k近邻分类器(k=3),在多种大小、架构及推理专用模型上,均能实现高精度的回复类型预测。
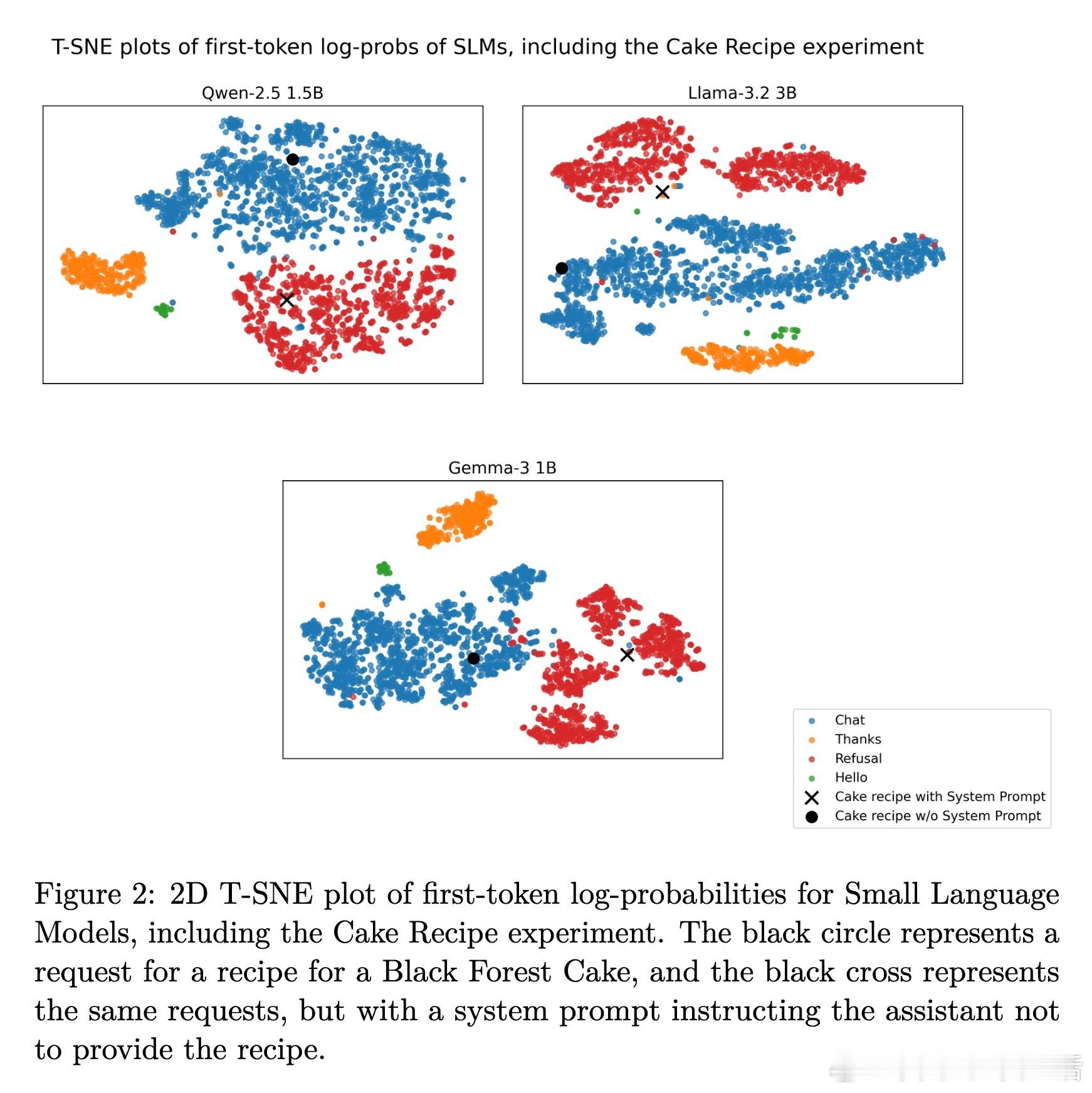
3. 方法适用拒绝类型,包括模型内置的安全策略拒绝和用户自定义的系统提示导致的拒绝。
4. 该技术可实现生成过程中的早期终止或将请求转给更小模型,显著降低计算成本与响应延迟。
数据集与实验:
- 构建了约3000条对话数据,覆盖拒绝、感谢、问候及普通聊天四类,数据来源包括AdvBench和Alpaca等。
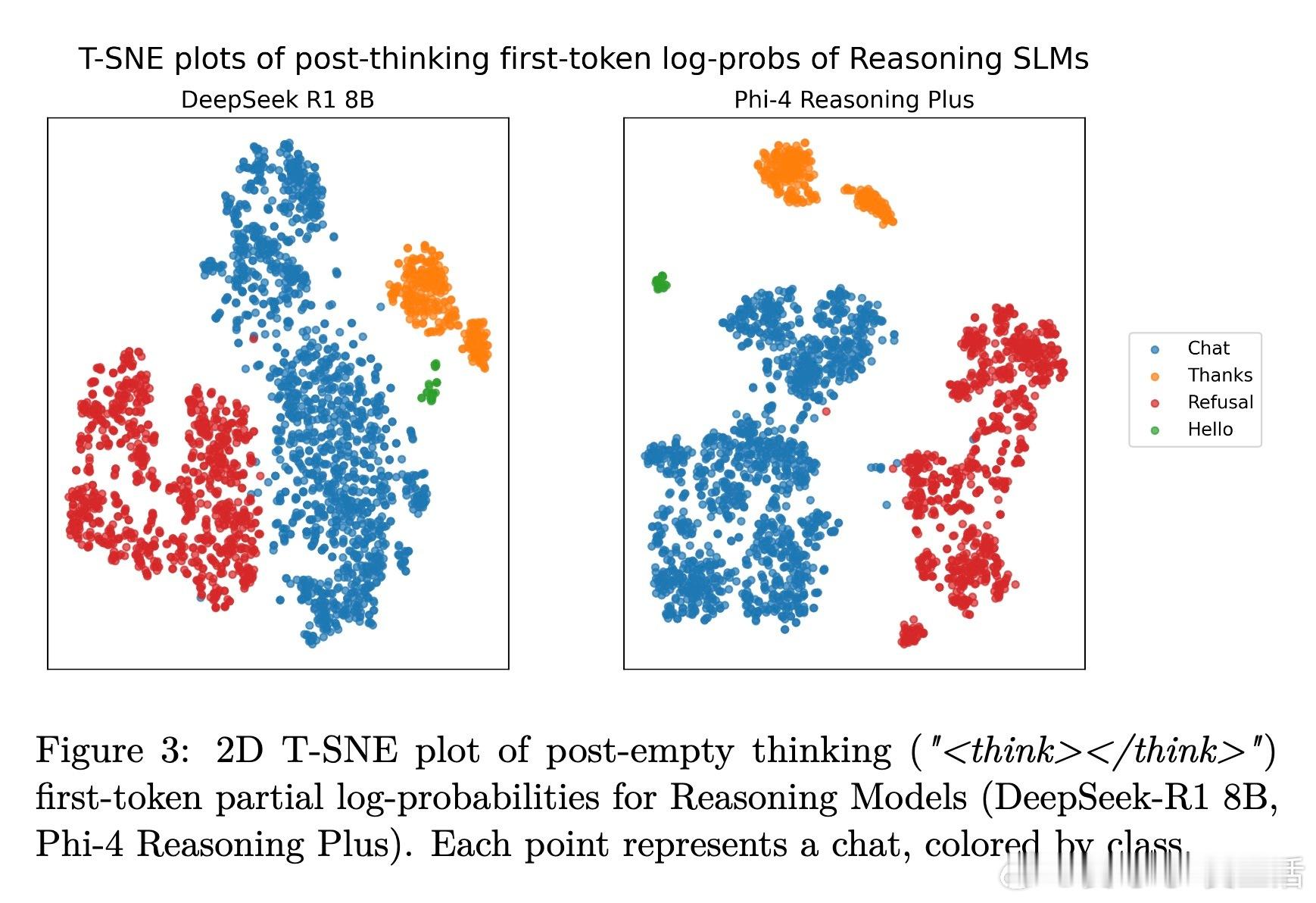
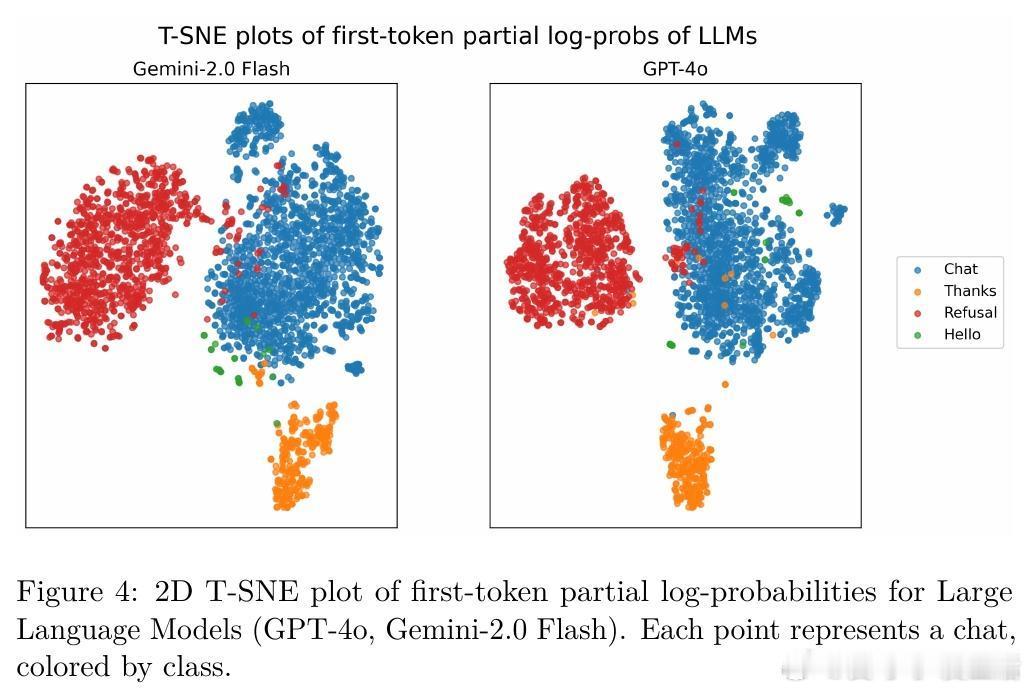
- 在Llama 3.2 3B、Qwen 2.5 1.5B、Gemma 3 1B等小型模型,以及DeepSeek-R1 8B、Phi-4 Reasoning Plus推理模型和云端GPT-4o、Gemini 2.0 Flash等大型模型上均验证了方法有效性。
- 可视化(t-SNE)清晰呈现第一词概率向量的类别分布;交叉验证F1均值超过0.99,表现卓越。
创新点与意义:
- 利用第一词概率分布预测回复类型,是对之前基于隐藏层激活或特殊拒绝标记方法的简化且无需额外训练的创新。
- 具备极低计算开销,适合实际部署中降低不必要的能耗与延迟,推动LLM系统更绿色可持续发展。
- 公开了数据集(),促进后续研究。
未来展望:
- 扩展至更多模板化回复类别、多语言及多模态场景。
- 结合模型内部表征,进一步提升早期预测的准确率和泛化能力。
该研究为提升大规模语言模型推理效率提供了切实可行的路径,兼具技术创新与环保价值,值得关注与借鉴。
原文链接:arxiv.org/abs/2510.22679